Data centres have been providing services to users for decades and the expectation has always been that system failures and interruptions would be kept to a minimum – and perhaps more importantly, that should something go wrong it would be fixed as quickly as possible.
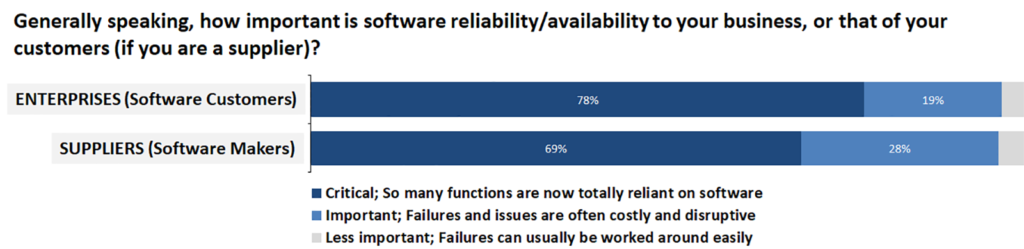
The problem is that the popular idea of what constitutes an acceptable minimum number of interruptions has fallen so low that many IT services are now expected simply to always work, without fail. And, goodness knows, if something does go wrong, the expectation is that it will be fixed within minutes, if not seconds. This has made software reliability a critical issue for both the vast majority of enterprise users and the technical staff whose job it is to keep everything running smoothly (Figure 1).
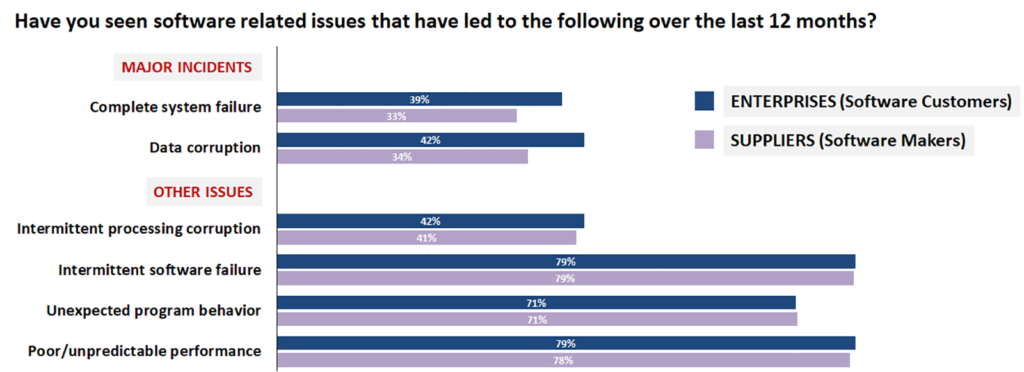
A recent report by Freeform Dynamics highlights the fact that despite considerable effort and expense, and the development of new architectures and operational processes, IT services still suffer interruptions. This is true across organisations of all sizes and in all verticals, and it applies to the producers of software as well as to the users of commercial applications (Figure 2).
Major incidents and intermittent problems abound
Over a third of respondents reported major incidents such as complete system failure and data corruption. But while major systems failures can have a huge impact, DR plans and procedures often exist to deal with them, with the expectation that key resources will be mobilised immediately. In some ways more challenging are issues that crop up and then disappear. If you’re lucky, such intermittent problems could simply be caused by bugs in the application software in sections that are only run in unusual circumstances, relatively easy to track down, if not always to remediate.
More problematic are failures that only take place due to an unusual combination of the application code execution within the overall systems environment, potentially including factors from the operating system, middleware stacks, virtualisation platforms or even the precise nature of the physical environment. And such unusual combinations of elements are more likely to happen as systems become more dynamic in terms of how resources are allocated at execution time.
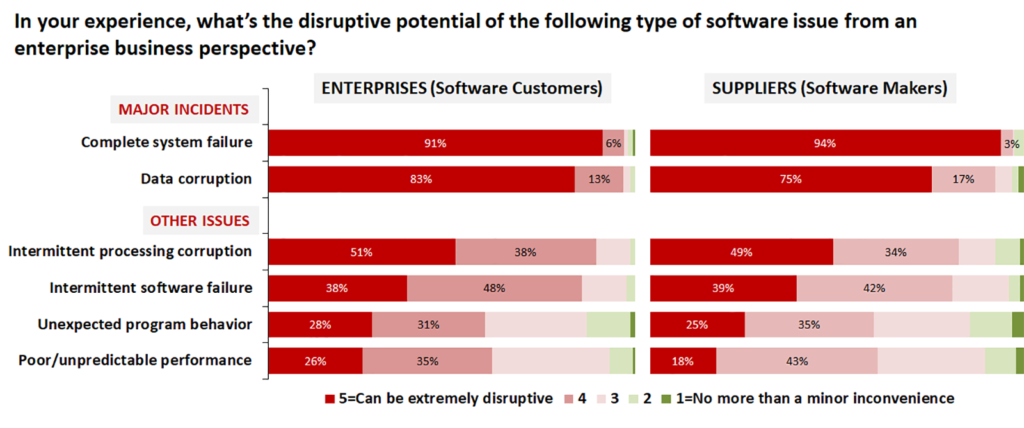
Indeed, more respondents stated they had experienced sporadic problems, such as intermittent software failure or intermittent processing corruption, unexpected program behaviour or unpredictable performance, as compared to those reporting major systems outages. And when it comes to the impact of these software issues, the survey paints a disturbing picture (Figure 3).
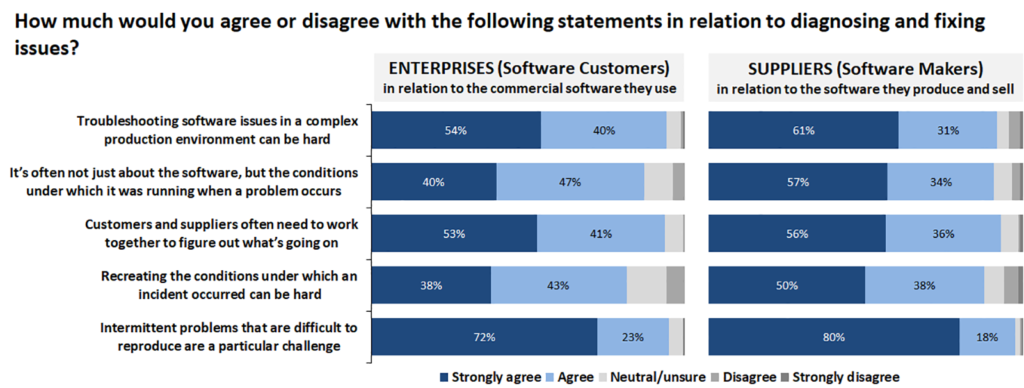
Major issues are, of course, almost without exception extremely disruptive, but intermittent problems are also recognised as being disruptive by many. Plus it’s not just corruption or unexpected behaviour that cause disruption – performance inconsistency is also important. Taken together, it is clear that the reliability and responsiveness of software are much more than simply nice-to-have features. But why do such issues cause data centre professionals problems (Figure 4)?
Anyone who has worked in an enterprise data centre will identify with it being hard to troubleshoot software issues in a complex environment. And as was mentioned earlier, the steady move towards dynamic and self-reconfiguring data centres is adding yet more intricacy to an already complex situation. Factor in the way that applications themselves are often constructed to access external services via API calls, and ‘complex’ is no longer an adequate description: ‘convoluted’ may be more accurate.
Merely recreating the conditions under which an incident occurred can be difficult, especially if there is no record of the precise conditions that were then in play. The results show that the difficulty of reproducing intermittent problems is a challenge for everyone. And over ninety percent of respondents reported that problems which drag on while no one can explain the cause have a major negative impact on business user and stakeholder confidence.
This indicates very clearly that it is not just major incidents that erode stakeholder confidence in both IT and the commercial suppliers of software. Once again, almost nine out of ten respondents said that even if they have relatively few big incidents, a constant stream of minor but irritating issues, or simply users having to use disruptive workarounds, can erode stakeholder confidence. The same can happen even if a problem is rapidly identified, but remediation takes a long time. A lack of stakeholder satisfaction is bad news for everybody – IT staff, software vendors and business users alike.
Is there an answer?
Every enterprise data centre has an abundance of management and monitoring tools at the disposal of IT staff, yet these problems still occur. So is there something else that could be used to help? In particular, the survey asked for thoughts on a relatively recent development, namely program execution ‘record and replay’ technology.
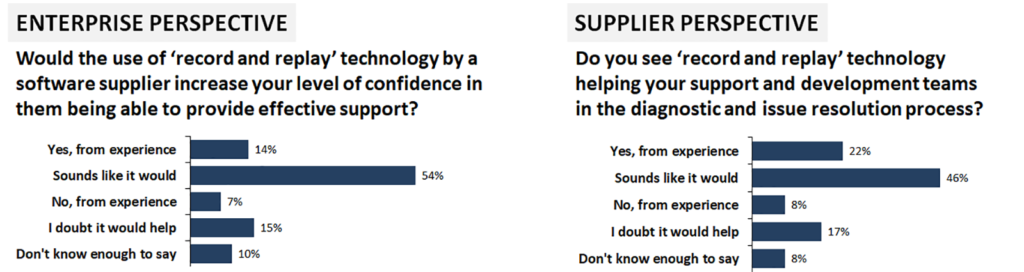
From a data centre perspective, it’s the equivalent of an aircraft’s ‘black box’ flight recorder for your production environment. Once enabled, it can give an accurate picture of the IT environment when a problem occurs, and of what the software actually did before it crashed or misbehaved. The idea is to catch failures in the act, thereby making them completely reproducible and greatly accelerating both diagnostics and issue resolution. But do IT professionals see value in such tools (Figure 5)?
The Bottom Line
The answer is a qualified “yes”. Relatively few IT professionals, from either the software vendor or enterprise data centre, have actively used this type of technology so far, but there is a consensus that it has potential, while only around a quarter of respondents think not. But as application technology evolves and software-defined data centres become more autonomous, we will see more of the highly variable, complex interlinked system environments where intermittent software problems are likely to occur. Record and replay technology could well have a significant role to play in keeping business users and customers happy, and just as importantly, in raising the perception of IT and software vendors in the eyes of the ultimate budget holders.
Tony is an IT operations guru. As an ex-IT manager with an insatiable thirst for knowledge, his extensive vendor briefing agenda makes him one of the most well informed analysts in the industry, particularly on the diversity of solutions and approaches available to tackle key operational requirements. If you are a vendor talking about a new offering, be very careful about describing it to Tony as ‘unique’, because if it isn’t, he’ll probably know.