

This article follows on from an earlier piece where the results of a survey of was used to illustrate the core state of business information and analytics in organisations today, including a review of which data types are most important and which are growing fastest. Here we look at how familiar organisations are with ‘Big Data’ as well as getting a glimpse of how far people believe such solutions are ready for mainstream adoption. In addition we will consider whether vendors and their channel partners are perceived to be able to help potential customers exploit such capabilities.
The survey was run during August and September of 2012 by Freeform Dynamics with participation from 502 readers of the Register (for sample breakdown see here).
Data and analytics – solution familiarity
Every IT professional understands that relational databases play an important role in most organisations. Indeed, the previous article in this series highlighted that such repositories are used to hold business critical data in many organisations. Such “traditional platforms” are not only widely deployed, they are also well understood, something that cannot be said for a number of more recent additions to information management armouries (Figure 1).
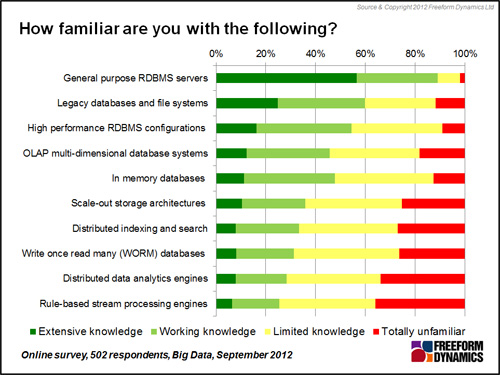
Figure 1
Indeed the chart above indicates that on average almost as many respondents have no familiarity with modern solutions such as scale-out storage, distributed search and indexing, WORM (Write Once, Read Many) databases, distributed data analytics and rules based stream processing as have a reasonable knowledge of them. Such results come from a web survey of a community likely to have a higher than normal number of respondents interested in ‘big data’ solutions. Experience therefore leads us to believe that the levels of understanding and working knowledge of these modern solutions is almost certainly even lower in the IT population as a whole.
Given the likely low levels of familiarity, just how widely deployed are these solutions, many of which could play significant roles in big data systems?
The technology of analytics and data storage
Taking into account the results of Figure 1, it comes as little surprise that relational databases and other “Legacy” platforms are very widely utilised. Specialist high performance RDBMS configurations are also well used. Amongst the other options only OLAP multi-dimensional databases and scale out storage platforms achieve significant levels of use in around one in five organisations. Beyond these, in line with the relatively low levels of understanding discussed above, other technologies and approaches have yet to make a major impact (Figure 2).
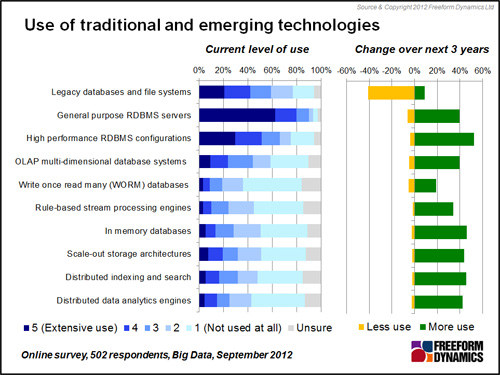
Figure 2
However it is already evident that much greater use of such systems is forecast by significant numbers of respondents. With such a welcome potentially close at hand, it will be interesting to see how rapidly the vendors of such solutions can educate broader sections of the general IT community to raise awareness and comfort levels.
There is another challenge hidden here that has been gnawing away for many years, one which big data and other infrastructure developments of the past few years are now throwing into the spotlight. This concerns the licensing models and costs associated with using database systems in modern environments (Figure 3).
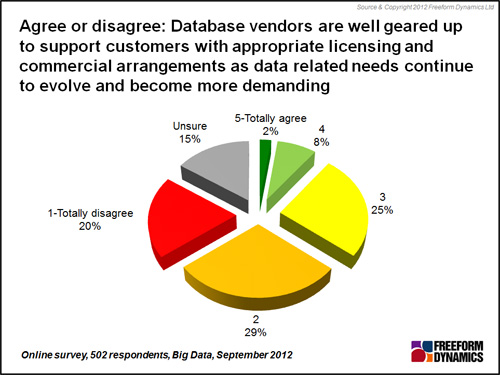
Figure 3
The chart highlights that only one in ten respondents are of the opinion that database vendors are ready to provide licensing models suited to their needs, especially as business requirements become ever more demanding. Nearly half give a categorical ‘No’ and disagree with the statement. Almost one in seven are unsure.
A couple of freeform comments from respondents in relation to licensing add a little colour:
“Whenever you are talking RDBMS, and management is fixed on avoiding open source solutions, you can count on the solution to be very expensive. It is also shocking to see all of the extras that sneak in over time and cost even more!”
And this comment really sums things up:
“While many vendors are talking the talk, when it comes to really performant enterprise solutions, they are not proactively offering us useful alternatives”
Even though the database vendor community is not alone in attracting such unhappiness in its licensing models, the despair evident here makes this a challenge that software vendors should ideally address in the short term. However, it’s evident that some are dragging their feet as they enjoy additional income from the mismatch between traditional commercial models and new deployment options.
So with understanding and use of “big data” solutions at relatively low levels, this raises the question of how pressing is the demand to implement such systems to analyse big data sources such as those emerging from high volume data streams?
High volume data feeds
In the emerging realm of big data, much is made of the potential for organisations to extract nuggets of valuable information from very large, unstructured data sources. One example of this envisages organisations analysing high volume data feeds such as event logs, click streams or security logs etc. in something approaching real time. But is there much demand to analyse such data pools? The answer is a qualified ‘yes’ (Figure 4).
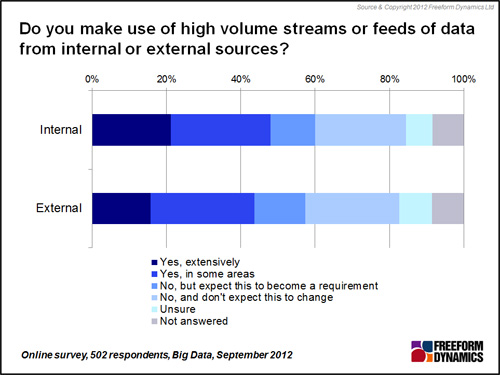
Figure 4
As can be seen from Figure 4, around one in five respondents report they already make extensive use of high volume data feeds from either internal or external sources, with over a quarter using such data sources in at least some areas of the business. Only around one in four states they do not make use of such feeds and don’t expect this to change.
But such numbers need to be considered in context of the web survey, whereby experience tells us it is likely that such a survey on big data is more likely to attract those already engaged, or at least interested, in these areas. So whilst we can state that high volume data feeds are already an important source of data for some organisations and are likely to grow, they have yet to become massive.
Thus quotes such as the ones below relating to examples of high volume external information sources that are important to our survey respondents need to be considered in context.
“We collect some state and initialization data from bespoke electronic systems, as well as integrating non-critical feeds from other end-user systems such as Twitter and Facebook, all in Realtime”.
We use .. “web clicks, data from Twitter, Facebook and other social media”
We record … “Web logs, click streams, impression logs, Data center usage data, to the per-core or per-VM level, CDR, IPDR, xDR, Financial quote streams / logs”
With clear potential for growth, just how well are vendors doing positioning their big data offerings and are they perceived to be ready to support deployment in businesses at large?
Big Data – understanding, vendor support and solution positioning
Given the lack of familiarity of new technology solutions, we asked a few questions to put things into the ‘Big Data’ context. To sum things up, it appears that a significant number of respondents believe that technology is now ready to help them address existing problems and tackle new challenges (Figure 5).