
If the deluge of headlines and vendor marketing materials is anything to go by, ‘big data’ is the ‘next big thing’. So how much is there really to all this ‘big data’ talk? Is it all about putting new labels on existing product offerings, as some would contend? Or is it the diametrically opposed view, a bunch of interesting but immature technologies that aren’t yet ready for enterprise deployment? And what about the demand side? Are companies asking for these solutions? Do they need them at all?
The short answer is “all of the above”. Yes, there are solutions out there where the only thing that’s changed is the label on the metaphorical box. Whether or not the new label is applicable depends on how one chooses to interpret ‘big data’. At the other end of the spectrum, there’s a collection of emerging solutions that indeed add new capabilities, even if many of these aren’t quite mainstream enterprise-ready.
But it’s also clear that there is demand for solutions throughout the spectrum of established and emerging ‘big data’ solutions, and the potential for advanced data storage, access and analytics technologies is recognised by IT professionals. This was confirmed in a recent Freeform Dynamics research study (122 respondents, November 2011, Figure 1).
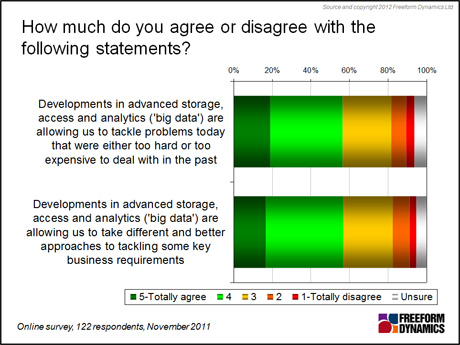
Figure 1
The need for new approaches and solutions also becomes clear when we look at the rate at which data volumes are growing, whether it’s data going into existing RDBMSs, documents stored on corporate servers, log files created by systems, web sites or devices, external data streams supporting business applications, or indeed data from a variety of social media environments. But it’s not only the increasing volume of data that’s causing headaches: nearly half the organisations in our survey aren’t making the most of the information assets they have residing in structured repositories, and hardly any are exploiting the data held outside of structured systems to any significant degree (Figure 2).
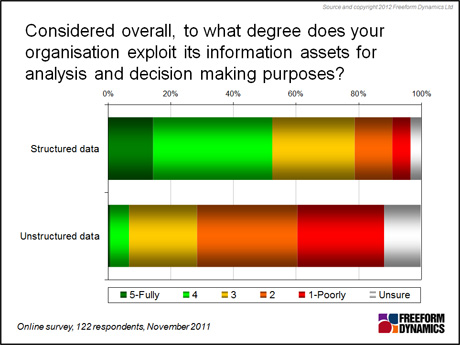
Figure 2
Being able to get more business value out of existing internal data assets is increasingly becoming a key requirement, whether it’s to achieve more granular levels of customer segmentation, augment existing OLAP engines, fine-tune fraud detection systems, react in real-time to events, prevent system failures in IT – the list goes on and on. With some of these information needs, the value to be derived is already reasonably clear, i.e. the company knows it has the data and what to look for, but needs to find a way, or an improved method, of storing, accessing, analysing and presenting it. In other cases, it’s not clear what value might be found: “panning for gold”, “finding a needle in the haystack”, and similar terms are typically used to describe these scenarios.
These different starting points have a major influence on technology selection, as companies aren’t prepared to make speculative investments in expensive solutions just in case there’s something to be found. This is where hybrid solutions come into play. Existing proprietary (and typically costly) storage and database solutions are being supplemented by some of the more cost-effective emerging technologies, typically from the Apache Hadoop ecosystem. Preliminary exploration and analysis of large data volumes, where the ‘nuggets’ are well hidden, can be carried out in a Hadoop environment. Once the ‘nuggets’ have been found and extracted, a reduced and more structured data set can then be fed into an existing data warehouse or analytics system.
From that perspective, it makes absolute sense for vendors of existing storage, database, data warehousing and analytics software to provide connectors and APIs to Hadoop solutions, or even put together integrated offerings that feature both the proprietary and open source elements. While some of this rush to embrace Hadoop is no doubt defensive, it’s overall a sensible and desirable move. As already mentioned, many of the new ‘big data’ technologies are not ready for mainstream enterprise usage, and companies without the IT capabilities of the trailblazers or typical early adopters will welcome the support from established vendors.
That’s not to say they believe they will get it. The signs are that the hype surrounding ‘big data’ is potentially hiding the real value of what’s already on offer. IT professionals remain very sceptical with regard to vendors’ ability to deliver, and claims that the end of the traditional RDBMS is nigh are simply not taken seriously (Figure 3). In addition, there is a belief that vendors aren’t well geared up to support their customers with appropriate licensing and commercial arrangements when it comes to evolving data-related needs.
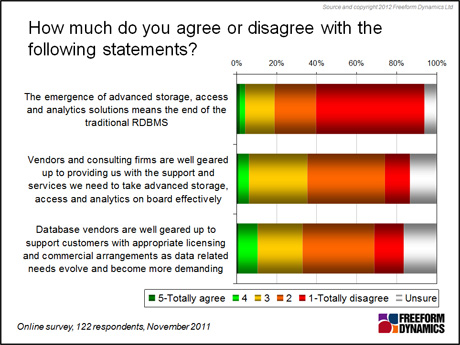
Figure 3
Overall, we’re looking at an environment in which there have been lots of technology advances, the value and potential of which are, or are beginning to be, recognised. But there is much work to be done. On the vendor side, concerns about over-hyping and ability to execute must be addressed. On the enterprise side, business and IT need to work together to decide which data assets are most worth exploiting, and what business value the results could bring. IT also needs to conduct a thorough assessment of what skills are available, what skills are needed, and how to bridge the gap. Otherwise, Big Disappointment will be the inevitable result.
CLICK HERE TO VIEW ORIGINAL PUBLISHED ON
![]()