
‘Big data’ is one of those ‘buzz’ terms that is difficult to avoid, at least by anybody who reads IT-related publications, or receives vendor marketing materials. From that perspective, ‘big data’ certainly is big. And as is typically the case with ‘buzz’ terms, there are not only serious technology developments but also serious business issues (and their potential solutions) behind the hype. But where are we when it comes to actual adoption of those technologies? And when does data become ‘big data’?
Let’s start with the last question. To many, the answer is simple: data becomes ‘big’ when you’re talking volumes ending in terabytes (TB), petabytes (PB), exabytes (EB) and beyond (yottabytes, anyone?). Others apply criteria such as a number of records, transactions, or files; if the number is mind-bogglingly large, then surely it must be ‘big data’. But that’s missing a crucial point about ‘big data’ – it’s not just about quantity, but also about the nature of the data. Put differently: just scaling up your existing systems to accommodate ever larger data volumes doesn’t necessarily mean you’re dealing with ‘big’ data. The ‘big’ comes into play when you’re looking at all the data that resides outside your existing, typically well-structured, systems and wondering how on earth you can harness it for business benefit.
Next, let’s get another definitional issue out of the way: ‘structured’ versus ‘unstructured’ data. Categorizing ‘structured’ data tends to be less contentious because this is data that exists in tabular form, typically in relational database management systems (RDBMS). And then there’s the rest. To call it ‘unstructured’ applies only in the sense that this data doesn’t reside in traditional RDBMSs. But there are many shades of grey. For example, the data in system or web logs is usually very well structured, and each data element has a known definition and set of characteristics. Likewise, data from a social media stream, like Twitter, is well-structured in some ways (e.g. defined length of message, use of operators such as @ or #), and yet is totally unstructured in others (e.g. the content of the message could be anything). Email, documents, spread sheets and presentations also fall into this category to a certain degree; it all depends on the context in which they are stored. Then there are blogs, pictures, videos and all kinds of other data elements which your organisation may well wish to understand better but doesn’t yet capture within existing systems.
Of course, there’s certainly no getting away from data growth. A recent survey* conducted by Freeform Dynamics shows that most organisations are seeing data volumes increase, with ‘unstructured’ data for many looking set to grow even faster than their ‘structured’ data, as illustrated in Figure 1.
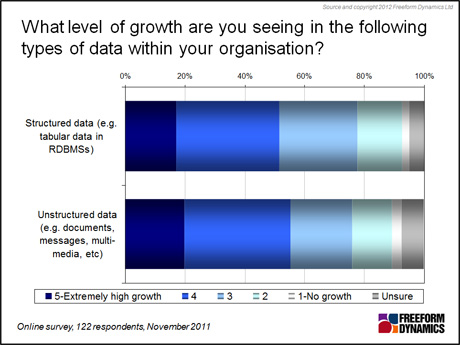
Figure 1
This is where the first check point comes for an organisation wondering whether ‘big data’ applies to them and what is the potential importance of being able to unlock value from the ‘unstructured’ data it has available? This is regardless of whether such data is created or collected inside the organisation, or arriving through external feeds. Most organisations have a strong gut feeling that there ‘must be something in there’ but haven’t got the means to get at ‘it’.
But how can you justify investing in technology and setting aside resources when you don’t even know what you’re looking for? Especially when it may not even be clear which technology might be best suited to this data equivalent of ‘panning for gold’.
This classic ‘chicken-and-egg’ situation is most likely one of the key reasons why few companies today are extracting value from information held outside systems designed for handling structured data, as shown in Figure 2.
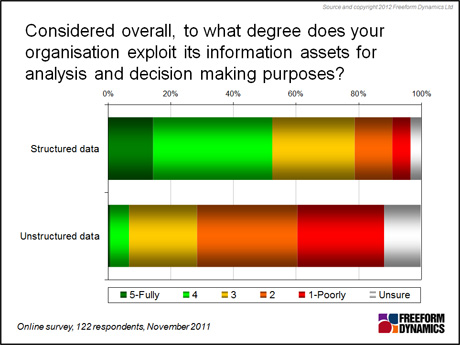
Figure 2
Nevertheless this dilemma is set to change, as developments in advanced storage, access and analytics come into play. Together, these help to address ‘big data’ problems not just by being able to crunch lots of data but also by doing so in innovative ways. And in many instances, they use commodity hardware and open source software, which in turn can reduce the cost of entry, provided of course the relevant skills are available within the organisation.
It goes beyond the scope of this brief article to go into ‘big data’ technologies in more detail. But before any technology decisions are even considered, business and IT executives need to identify whether they’re really in ‘big data’ territory in the first place, by applying the ‘three Vs’ test: volume, variety, and velocity.
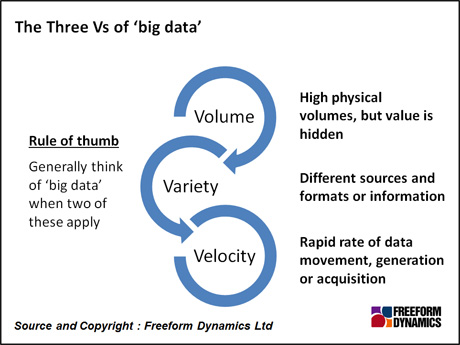
Figure 3
As described in Figure 3, the Three Vs together capture the essence of ‘big data’. This is of course just an artificial construct, albeit a very useful one that is becoming increasingly accepted. How an organisation applies the definitions and criteria is, of course, a matter for discretion. What’s most important is having – or gaining – a clear understanding of the organisation’s data landscape, how that is used today and whether there is a reasonable chance that further useful information might be extracted, above and beyond what’s already being done.
_____________________
* Online survey conducted during first half of November 2011; 122 responses. Organisation size ranging from under 50 employees to 50,000 and above. Respondents mainly IT professionals, with 55% based in the UK, 17% in the rest of Europe, 16% in the USA, and 12% in the rest of the world.
CLICK HERE TO VIEW ORIGINAL PUBLISHED ON
![]()
Content Contributors: Martha Bennett
Through our research and insights, we help bridge the gap between technology buyers and sellers.




Have You Read This?
From Barcode Scanning to Smart Data Capture
Beyond the Barcode: Smart Data Capture
The Evolving Role of Converged Infrastructure in Modern IT
Evaluating the Potential of Hyper-Converged Storage
Kubernetes as an enterprise multi-cloud enabler
A CX perspective on the Contact Centre
Automation of SAP Master Data Management
Tackling the software skills crunch